La función de este artículo es dar ejemplos de comunicación inalámbrica entre dos placas Arduino, utilizando el módulo transceptor basado en el chip NRF24L01.
En la imagen se observa dos formatos de módulo transceptor, ambos con el chip NRF24L01. Este chip utiliza la banda de 2,4 GHz y puede operar con velocidades de transmisión de 250 kbps hasta 2 Mbps. Si se usa en espacios abiertos y, con menor velocidad de transmisión, su alcance puede llegar hasta los 100 metros. Para mayores distancias, hasta 1000 metros, existen módulos provistos con una antena externa en lugar de una antena trazada sobre la misma placa, como se observa en la imagen.
Con este sistema enviaremos comandos de texto que controlen un módulo de relés para manejar artefactos de 220V CA en una instalación de domótica. Para domótica es suficiente el alcance del módulo básico, pero se puede optar por la versión con antena incorporada, si es necesario.

En nuestro artículo Arduino: Comunicación inalámbrica con NRF24L01 están explicados y desarrollados en detalle varios usos del módulo NRF24L01 con un Arduino. Si no está familiarizado con un módulo como este, o si desea profundizar más en sus características y capacidades, recomendamos su lectura, aunque no es imprescindible para utilizar este diseño.
Para el control de las placas NRF24L01 para enlace de RF se utiliza la biblioteca RF24, totalmente compatible con las placas Arduino. En la página enlazada hay una explicación en inglés de cómo instalarla en su IDE de Arduino. Si no, puede leer las instrucciones a continuación (si ya conoce el procedimiento, saltee esta explicación):
Como es una librería obtenida del sitio GitHub, que es un repositorio de código para programadores, deberemos utilizar el método de instalación manual. Lo primero es descargar la librería en formato ZIP dentro de la carpeta que usted elija.
Una vez descargada debemos añadir la librería mediante el menú desplegable Programa >> Incluir Librería >> Añadir biblioteca .ZIP… Se abrirá un panel para buscar el ZIP en su disco rígido.

Una vez seleccionado el archivo éste será incluido. Cerramos el IDE de Arduino y cuando volvamos a abrirlo la librería ya estará disponible.
Circuito básico para el sistema
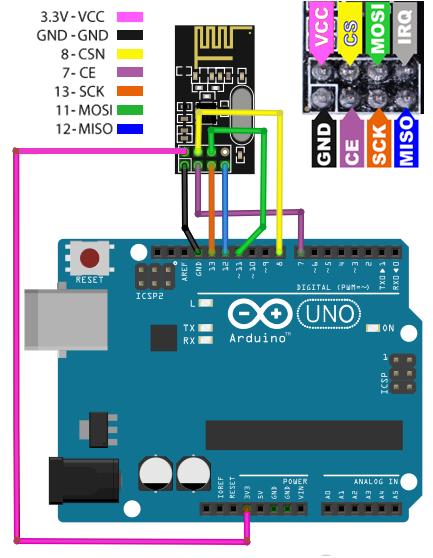
La biblioteca RF24 utiliza los pines estándar del hardware SPI (MISO, MOSI, SCK) que son, respectivamente, los pines digitales 12, 11 y 13 en la placa Arduino UNO. También se necesitan dos pines adicionales para controlar las funciones de selección del chip (CS) y habilitación del chip (CE).
Estos dos últimos pines pueden ser elegidos y designados por el usuario utilizando la función radio(ce_pin, cs_pin) de la biblioteca RF24; y se puede usar cualquier pin digital disponible.
El diagrama de conexiones de los módulos —que mostramos a continuación— es idéntico para las placas Arduino de ambos lados, transmisor y receptor. Observe con atención que la entrada VCC del módulo transceptor está conectada a la salida 3,3V del Arduino. No se equivoque con la alimentación poniéndola a 5V, porque el módulo resultaría dañado.
A continuación, le agregaremos a uno de los dos Arduino, que funcionará de receptor, un módulo de relés como los que hemos descrito y explicado en detalle en el artículo Módulos de relé y Arduino: Domótica (1). Recomendamos leerlo.
Sistema 1: Control utilizando el teclado de la computadora a través de Monitor Serie
La placa Arduino utilizada como transmisor estará conectada al puerto USB de la PC, o laptop, que utilizamos para programarlo y luego para enviar los comandos. El puerto USB alimentará la placa y el módulo transmisor.
El Arduino receptor puede estar conectado a cualquiera de los modos de alimentación adecuados: un cable USB conectado a un cargador estándar de 5V, o a un Power Bank para celular; una batería de 9V o una fuente regulada de 9V CC conectada al jack de entrada de alimentación de la placa Arduino o a su pin Vin.
El circuito del receptor se cableará de la siguiente manera a los módulos de relé:
Nota: en este circuito se alimentan los led emisores de los optoacoples desde la misma fuente de los relés. Para separar totalmente los circuitos, quitar el jumper entre VCC y JD-VCC y alimentar VCC desde los 5V de la placa Arduino.
Circuito del Sistema 1, con módulo de 2 relés

Criterio de control:
La lista de comandos es como sigue
a – Activa el relé 1 / a apaga el relé 1 al pulsar de nuevo
b – Activa el relé 2 / b apaga el relé 2 al pulsar de nuevo
Programa del transmisor
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 |
#include <SPI.h> #include <RF24.h> RF24 radio(7,8); // CE, CSN const byte identificacion[6] = "00001"; // cualquier juego de 5 letras y numeros void setup() { Serial.begin(9600); // Inicia comunicacion hacia el Monitor Serie radio.begin(); radio.openWritingPipe(identificacion); radio.setPALevel(RF24_PA_MIN); // Opciones RF24_PA_MIN, RF24_PA_LOW, RF24_PA_HIGH, RF24_PA_MAX // MIN = -18dBm, LOW = -12dBm, HIGH = -6dBm, MAX = 0dBm radio.stopListening(); } void loop() { char caracter; if (Serial.available() > 0) { caracter = Serial.read(); if (sizeof(caracter) == 1) { radio.write(&caracter, 1); } } } |
Programa del receptor:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 |
#include <SPI.h> #include <RF24.h> #define encender LOW // definicion de valores para accionar reles #define apagar HIGH int rele1 = 2; // definicion de nombres de salidas int rele2 = 3; RF24 radio(7,8); // CE, CSN const byte identificacion[6] = "00001"; // cualquier juego de 5 letras y numeros void setup() { pinMode(rele1,OUTPUT); digitalWrite(rele1,apagar); // Rele 1 pinMode(rele2,OUTPUT); digitalWrite(rele2,apagar); // Rele 2 radio.begin(); radio.openReadingPipe(0, identificacion); radio.setPALevel(RF24_PA_MIN); // Opciones RF24_PA_MIN, RF24_PA_LOW, RF24_PA_HIGH, RF24_PA_MAX // MIN = -18dBm, LOW = -12dBm, HIGH = -6dBm, MAX = 0dBm radio.startListening(); // inicio de recepcion } void loop() { /**************************************************************/ if (radio.available()) { char texto[2]; radio.read(&texto,1); // Esperamos que llegue algo por RF desde el modulo if (sizeof(texto)>0) { /**************************************************************/ controlEncendido(texto[0]); } } } // rutina auxiliar void controlEncendido(char val) { int valor = 0; switch (val) { case 'a': valor = !digitalRead(rele1); digitalWrite(rele1,valor); // RELE 1 apagado break; case 'b': valor = !digitalRead(rele2); digitalWrite(rele2,valor); // RELE 2 apagado break; case '0': digitalWrite(rele1,apagar); digitalWrite(rele2,apagar); // Todos apagados break; default: break; } } |
Con esta disposición, la manera de controlar los relés es como sigue: abrimos el panel de Monitor Serie y tipeamos allí los comandos “a” o “b” para encender y apagar los relés.
La capacidad de control se puede ampliar utilizando módulos de mayor tamaño, por ejemplo de 4, 8 o 16 relés, y agregando las variables y líneas de programa para cada relé. Utilizaremos en esos casos las siguientes letras: “c”, “d” y así sucesivamente.
Sistema 2: Control con pulsadores, sin necesidad de computadora
Con el sistema desarrollado en la primera parte dependemos de una computadora para ingresar los comandos al Arduino transmisor, y esto puede ser impráctico.
Para agregar un nivel más de independencia al control, conectaremos unos pulsadores al circuito transmisor de Arduino que ya presentamos. Para que nos resulte más simple, vamos a utilizar los pulsadores de RESET con cable y conector que es posible rescatar por desarme del panel frontal de cualquier PC de mesa que haya sido descartada. Como este:

Si usted lo desea, puede reemplazar los dos pulsadores por cualquier modelo que usted disponga, como estos (colocados sobre una protoboard y conectados con cables), que además de venir en los kits básicos de Arduino, son muy comunes en electrónica:

Diagrama para el Sistema 2: pulsadores y módulo de 2 relés
Hemos agregado dos pulsadores de panel frontal de computadora de mesa, que ingresan por las entradas digitales 2 y 3. Los pulsadores los hemos nombrado como Puls1 y Puls2.
Con estos pulsadores podremos controlar el módulo de dos relés con el que trabajamos en este artículo hasta ahora, pero podríamos implementar este control con módulos de 8, 16, y hasta 32 relés.
El diagrama para esta parte del proyecto —siempre manteniendo el cableado básico del Arduino con el NRF24L01— es:
![]()
Criterio de control:
La lista de comandos es como sigue
Puls1 – Activa el relé 1 / Puls1 apaga el relé 1 al pulsar de nuevo
Puls2 – Activa el relé 2 / Puls2 apaga el relé 2 al pulsar de nuevo
Programa del transmisor:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 |
#include <SPI.h> #include <RF24.h> RF24 radio(7, 8); // CE, CSN const byte identificacion[6] = "00001"; int Puls1 = 2; int Puls2 = 3; void setup() { pinMode(Puls1,INPUT_PULLUP); // se define la entrada con un resistor a 5V (pullup) pinMode(Puls2,INPUT_PULLUP); // se define la entrada con un resistor a 5V (pullup) Serial.begin(9600); // Iniciamos la comunicacion serie hacia el Monitor Serie en la PC radio.begin(); radio.openWritingPipe(identificacion); radio.setPALevel(RF24_PA_MIN); radio.stopListening(); } void loop() { char caracter = ""; if (digitalRead(Puls1) == 0) { delay(10); // filtro de rebote mecanico if (digitalRead(Puls1) == 0) { caracter = "a"; radio.write(&caracter, 1); while (digitalRead(Puls1) == 0) { } // espera a que se suelte el pulsador } } else if (digitalRead(Puls2) == 0) { delay(10); // filtro de rebote mecanico if (digitalRead(Puls2) == 0) { caracter = "b"; radio.write(&caracter, 1); while (digitalRead(Puls1) == 0) { } // espera a que se suelte el pulsador } } delay(500); } |
Programa del receptor:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 |
#include <SPI.h> #include <RF24.h> #define encender LOW // definicion de valores para accionar reles #define apagar HIGH int rele1 = 2; // definicion de nombres de salidas int rele2 = 3; RF24 radio(7,8); // CE, CSN const byte identificacion[6] = "00001"; // cualquier juego de 5 letras y numeros void setup() { pinMode(rele1,OUTPUT); digitalWrite(rele1,apagar); // Rele 1 pinMode(rele2,OUTPUT); digitalWrite(rele2,apagar); // Rele 2 radio.begin(); radio.openReadingPipe(0, identificacion); radio.setPALevel(RF24_PA_MIN); // Opciones RF24_PA_MIN, RF24_PA_LOW, RF24_PA_HIGH, RF24_PA_MAX // MIN = -18dBm, LOW = -12dBm, HIGH = -6dBm, MAX = 0dBm radio.startListening(); // inicio de recepcion } void loop() { /**************************************************************/ if (radio.available()) { char texto[2]; radio.read(&texto,1); // Esperamos que llegue algo por RF desde el modulo if (sizeof(texto)>0) { /**************************************************************/ controlEncendido(texto[0]); } } } // rutina auxiliar void controlEncendido(char val) { int valor = 0; switch (val) { case 'a': valor = !digitalRead(rele1); digitalWrite(rele1,valor); // RELE 1 apagado break; case 'b': valor = !digitalRead(rele2); digitalWrite(rele2,valor); // RELE 2 apagado break; default: break; } } |
Presionando el pulsador 1 se activará el relé 1, y con una nueva pulsación se lo desactiva. El funcionamiento es igual para el pulsador 2 en conjunto con el relé 2.
Nota: Si usted halla un error, por favor háganos saber que lo ha encontrado. Gracias.
Artículos relacionados:
■ Módulos de relé y Arduino: Domótica (1)
■ Control con relés por interfaz serie: Domótica (2)
■ Control de relés con control remoto IR: Domótica (3)
■ Control de relés por enlace de 2,4 GHz – módulos NRF24L01: Domótica (4)
■ Descripción y funcionamiento del Bus I2C
■ ¿Qué es la comunicación serie?