La electrónica integrada se conforma con circuitos interconectados (procesadores u otros circuitos integrados) para crear un sistema en el que están repartidas las funciones. Para que esos circuitos individuales intercambien su información, deben compartir un protocolo de comunicación común. Se han definido muchos protocolos de comunicación para lograr este intercambio de datos y, esencialmente, cada uno puede ubicarse en una de dos categorías: 1. Paralelo o 2. Serie.
Paralelo versus serie
Las interfaces paralelas transfieren múltiples bits simultáneamente. Por lo general, requieren barras (buses) de datos, que se transmiten a través de ocho, dieciséis o más cables. Los datos se transfieren en amplios oleajes de 1s y 0s.

Un bus de datos de 8 bits, controlado por un reloj,
que transmite un byte por cada pulso de reloj. Se utilizan 9 líneas
En cambio, las interfaces serie transmiten sus datos un bit a la vez. Estas interfaces pueden operar con tan solo un cable, por lo general nunca más de cuatro.
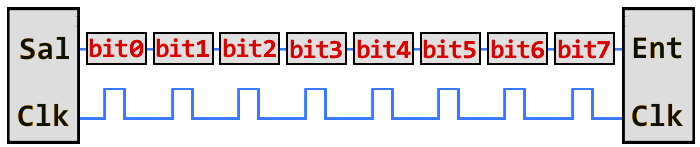
Ejemplo de una interfaz serie, transmitiendo un bit cada pulso de reloj. Solo se requieren 2 cables
Piense en las dos interfaces como una fila de automóviles: una interfaz paralela sería una autopista de 8 carriles o más, mientras que una interfaz en serie es más parecida a una carretera de dos carriles. Durante un lapso determinado, la autopista tiene el potencial de llevar a más personas a destino, pero en muchos casos ese sistema sencillo de dos carriles responde a su propósito, y construirlo cuesta una fracción de los fondos.
La comunicación paralela ciertamente tiene sus beneficios. Es rápida, directa y relativamente fácil de implementar. Pero requiere muchas más líneas de entrada/salida (E/S). Si alguna vez ha tenido que traspasar un proyecto de un Arduino Mega a un Arduino UNO básico, sabe que las líneas de E/S en un microprocesador pueden ser preciosas por lo limitadas. Por lo tanto, cada vez más optamos por la comunicación en serie, sacrificando una velocidad potencial para ahorrar pines.
Serie asíncrono (asincrónico)
A lo largo de los años, se han creado docenas de protocolos en serie para satisfacer las necesidades particulares de los sistemas integrados. USB (Universal Serial Bus = Bus Serie Universal) y Ethernet son dos de las interfaces serie de computación más conocidas en la actualidad. Otras interfaces serie muy comunes son SPI (del inglés Serial Peripheral Interface), I²C (del inglés Inter-Integrated Circuit) y el interfaz serie estándar TX/RX, del que hablaremos aquí. Estas interfaces serie pueden clasificarse en uno de dos grupos: sincrónico o asincrónico.
Una interfaz serie sincrónica siempre necesita tener una señal de reloj junto a las líneas de datos, por lo que todos los dispositivos en un bus serie sincrónico comparten un pulso común de reloj. Esto hace que en una transferencia en serie más directa, a menudo más rápida, también se requiera al menos un cable adicional entre los dispositivos de comunicación. Entre los ejemplos de interfaces sincrónicas están SPI e I²C.
Asincrónico significa que los datos se transfieren sin el respaldo de una señal de reloj conectada entre sistemas. Este método de transmisión es ideal para minimizar los cables necesarios, y en consecuencia la cantidad de pines de E/S utilizados, pero implica que debemos poner un poco de esfuerzo adicional en transferir y recibir datos de manera confiable. El protocolo en serie que analizaremos es la forma más común para las transferencias asincrónicas. De hecho, es tan común que cuando la mayoría de la gente dice «en serie», “o serial”, están hablando sobre este protocolo.
El protocolo serie sin reloj que analizaremos se usa ampliamente en electrónica integrada. Si está buscando agregar un módulo serie GPS, Bluetooth, XBee, LCD, o muchos otros dispositivos externos a su proyecto, es probable que necesite un interfaz serie.
Reglas de la comunicación serie
El protocolo serie asincrónico tiene una serie de reglas integradas: mecanismos que ayudan a garantizar transferencias de datos sólidas y sin errores. Estos mecanismos, que obtenemos para evitar la señal del reloj externo, son:
■ Bits de datos
■ Bits de sincronización
■ Bits de paridad
■ Velocidad en baudios
Teniendo en cuenta la variedad de estos mecanismos de señalización, vemos que no hay una sola manera de enviar datos en serie. El protocolo es altamente configurable. La parte crítica es asegurarse de que ambos dispositivos en una línea serie estén configurados para usar exactamente los mismos protocolos.
Velocidad en baudios
La especificación de velocidad de transmisión indica qué tan rápido se envían los datos a través de una línea serie. Normalmente se expresa en unidades de bits por segundo (bps). Si se invierte la velocidad en baudios, se puede averiguar cuánto tiempo se tarda en transmitir cada bit. Este valor determina durante cuánto tiempo el transmisor mantiene en alto/bajo una línea serie, o a qué velocidad muestrea su línea el dispositivo receptor.
Las velocidades en baudios pueden ser casi cualquier valor dentro de lo que permite el hardware. El único requisito es que ambos dispositivos funcionen a la misma velocidad. Una de las velocidades en baudios más comunes, especialmente para cosas simples donde la velocidad no es crítica, es de 9600 bps. Otras velocidades en baudios «estándar» son 1200, 2400, 4800, 19200, 38400, 57600 y 115200.
Cuanto mayor sea la velocidad en baudios, más rápido se envían/reciben los datos, pero existen límites para la velocidad a la que se pueden transferir los datos. Por lo general, no verá velocidades superiores a 115200, lo que es suficientemente rápido para la mayoría de los microcontroladores. Aumente demasiado y comenzará a ver errores en el extremo receptor, ya que los pulsos de reloj y los períodos de muestreo no pueden mantenerse.
Estructurando los datos
Cada bloque de datos (generalmente un byte) que se transmite se envía en realidad en un paquete de bits. Los paquetes se crean agregando bits de sincronización y paridad a nuestros datos.

Algunos símbolos en la estructura del paquete tienen tamaños de bits que son configurables.
Vamos a entrar en los detalles de cada una de estas partes de la estructura del paquete, o bloque.
Bloque de datos
La verdadera sustancia de cada paquete serie es la información que lleva. Ambiguamente llamamos a este bloque de datos un “bloque”, porque su tamaño no está específicamente establecido. En este estándar, la cantidad de datos en cada paquete se puede establecer en valores de 5 a 9 bits. Ciertamente, el tamaño de datos clásico es un byte de 8 bits, pero se usan otros tamaños. Un bloque de datos de 7 bits puede ser más eficiente que 8 si solo está transfiriendo caracteres ASCII de 7 bits.
Después de acordar la longitud para un caracter, ambos dispositivos serie también tienen que acordar el formato de sus datos. ¿Se envían los datos desde el bit más significativo (most significative bit = msb) al menos significativo, o viceversa? Si no se indica lo contrario, generalmente se puede asumir que los datos se transfieren enviando primero el bit menos significativo (least significative bit = lsb).
Bits de sincronización
Los bits de sincronización son dos o tres bits especiales transferidos con cada porción de datos. Son el bit de inicio y el(los) bit(s) de parada. Tal como indica su nombre, estos bits marcan el principio y el final de un paquete. Siempre hay un único bit de inicio, pero la cantidad de bits de parada se puede configurar en uno o dos (aunque normalmente se deja en uno).
El bit de inicio siempre se indica mediante una línea de datos inactiva que pasa de 1 a 0 (ALTO a BAJO). Los bits de parada volverán al estado inactivo manteniendo la línea en 1 (ALTO).
Bits de paridad
La paridad es una forma de comprobación de errores muy simple y de bajo nivel. Se presenta en dos variantes: impar o par. Para generar el bit de paridad, se suman todos los bits del byte de datos (5 a 9), y el resultado de la suma define si el bit es 1 o 0. Por ejemplo, suponiendo que la paridad se establece en par y se agrega a un byte de datos como 0b01011101, que tiene una cantidad impar de 1s (5), el bit de paridad quedaría en 1. Por el contrario, si el modo de paridad se configuró en impar, el bit de paridad sería 0.
La paridad es opcional, y no se usa mucho. Puede ser útil para transmitir a través de medios ruidosos, pero también ralentizará un poco la transferencia de datos y requiere que tanto el transmisor como el receptor implementen el manejo de errores (generalmente, si se detecta error, los datos recibidos con falla deben reenviarse).
Un ejemplo
9600 8N1 – 9600 baudios, 8 bits de datos, sin paridad y 1 bit de parada: es uno de los protocolos serie más utilizados. Entonces, ¿cómo se vería un paquete o dos de datos de 9600 8N1?
Un dispositivo que transmita los caracteres ASCII ‘O’ y ‘K’ tendría que crear dos paquetes de datos. El valor ASCII de O (en mayúsculas) es 79, que se divide en un valor binario de 8 bits de 01001111, mientras que el valor binario de K es 01001011. Todo lo que queda es agregar bits de sincronización.
No se establece específicamente, pero la norma más aceptada es que los datos se transfieren enviando primero el bit menos significativo. Observe cómo se envía cada uno de los dos bytes a medida que se lee de derecha (bit 0) a izquierda (bit 7).

Dado que estamos transfiriendo a 9600 bps, el tiempo empleado en mantener cada uno de esos bits alto o bajo es 1/9600 (bps) o 104 µs por bit.
Por cada byte de datos transmitidos, en realidad como mínimo se envían 10 bits: un bit de inicio, 8 bits de datos y un bit de parada. Entonces, a 9600 bps, en realidad estamos enviando 9600 bits por segundo o 960 (9600/10) bytes por segundo.
Ahora que sabemos cómo construir paquetes serie, podemos pasar a la sección de hardware. Allí veremos cómo esos 1s y 0s, y la velocidad de transmisión, se implementan a un nivel de señal.
Cableado y Hardware
Un bus serie consta de solo dos cables, uno para enviar datos y otro para recibir. Entonces, los dispositivos serie deben tener dos pines serie: el receptor: RX y el transmisor: TX.
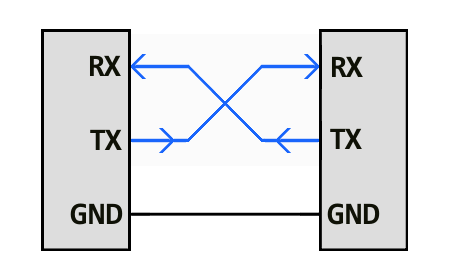
Cableado en serie
Es importante tener en cuenta que esas etiquetas RX y TX son con respecto al dispositivo en sí. Entonces, el RX de un dispositivo debe ir al TX del otro y viceversa. Es extraño si uno está acostumbrado a conectar Vcc con Vcc, GND con GND, MOSI con MOSI, etc., pero —pensándolo— tiene sentido. El transmisor debe estar comunicándose con un receptor, no con otro transmisor.
Una interfaz en serie en la que ambos dispositivos pueden enviar y recibir datos es dúplex completo (full-duplex) o semidúplex. Full-duplex significa que ambos dispositivos pueden enviar y recibir simultáneamente. La comunicación semidúplex significa que los dispositivos serie deben turnarse para enviar y recibir.
Algunas conexiones serie pueden implementarse con una sola línea entre un dispositivo de transmisión y un dispositivo de recepción. Por ejemplo, los LCD que tienen conexión serie son solo receptores, y realmente no tienen ningún tipo de información para devolver al dispositivo de control. Esto es lo que se conoce como comunicación serie simplex. Todo lo que necesita es un solo cable desde la transmisión del dispositivo maestro a la línea RX del que recibe.
Implementación de hardware
Hasta ahora fue una cobertura de la comunicación serie asíncrona desde un lado conceptual. Sabemos qué cables necesitamos, pero, ¿cómo se implementa realmente la comunicación en serie a nivel de señal? En una variedad de formas, en realidad. Hay todo tipo de estándares para la comunicación en serie. Veamos algunas de las implementaciones de hardware más populares de serie: nivel lógico o TTL, y RS-232.
Cuando los microcontroladores y otros circuitos integrados de bajo nivel se comunican en serie, generalmente lo hacen a un nivel TTL (Transistor Transistor Logic = Lógica Transistor-Transistor). Las señales serie TTL están en el rango del voltaje que alimenta a un microcontrolador, generalmente de 0V a 3,3V, 0V o 5V. Una señal en el nivel VCC (3,3V, 5V, etc.) indica una línea inactiva, un bit de valor 1 o un bit de parada. Una señal de 0V (GND) representa un bit de inicio o un bit de datos de valor 0.

El protocolo RS-232, que se puede encontrar en algunas de las computadoras y periféricos más antiguos, es como una interfaz serie TTL puesta cabeza abajo. Las señales RS-232 generalmente oscilan entre -13V y 13V, aunque la especificación permite cualquier cosa desde +/- 3V a +/- 25V. En estas señales, un voltaje bajo (-5V, -13V, etc.) indica la línea inactiva, un bit de parada o un bit de datos de valor 1. Una señal RS-232 alta significa un bit de inicio o un bit de datos de valor 0. Eso es lo contrario del protocolo TTL.
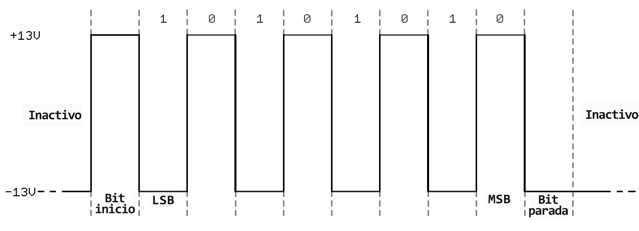
Entre los dos estándares de señal en serie, el TTL es mucho más fácil de implementar en circuitos integrados. Sin embargo, los niveles de baja tensión son más susceptibles a sufrir pérdidas en las líneas de transmisión largas. El RS-232 o estándares más complejos —como RS-485— son más adecuados para transmisiones en serie de largo alcance.
Cuando conecte dos dispositivos serie juntos, es importante asegurarse de que coincidan los voltajes de su señal. No se puede conectar directamente un dispositivo serie TTL con una línea RS-232. Se deben adaptar esas señales.
Continuando, exploraremos la herramienta que usan los microcontroladores para convertir sus datos que se encuentran presentes en un bus paralelo desde y hacia una interfaz serial: se llama UART.
UARTs
La última pieza de este armado en serie es encontrar algo para crear los paquetes en serie y controlar las líneas de hardware físico. Esto se concreta con un módulo llamado UART (Universal Asynchronous Receiver/Transmiter = Receptor/Transmisor Asíncrono Universal).
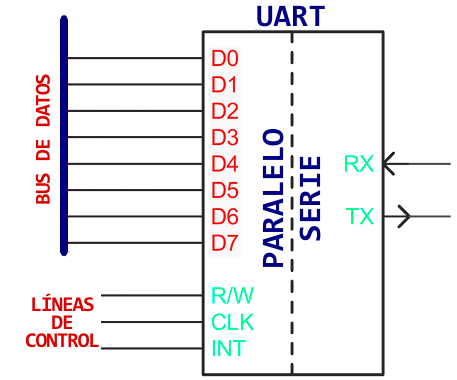
Un receptor/transmisor asíncrono universal es un bloque de circuitos responsable de implementar la comunicación en serie. En esencia, este UART actúa como un intermediario entre las interfaces paralelas y seriales. En un extremo del UART hay un bus de ocho o más líneas de datos (más algunos pines de control), en el otro lado están los dos cables serie: RX y TX.
UART simplificado
Los UART existen como circuitos integrados independientes, pero en la actualidad es más común que se encuentren dentro de los microcontroladores. Debemos consultar la hoja de datos de un microcontrolador para ver si tiene algún UART. Algunos no tienen, otros tienen uno, otros tienen varios. Por ejemplo, el Arduino UNO, basado en el «antiguo y fiel» ATmega328, tiene un solo UART, mientras que el Arduino Mega, construido sobre un ATmega2560, tiene cuatro UART.
Como lo indican las letras R y T en el acrónimo, los UART son responsables de enviar y recibir datos en serie. En el lado de transmisión, un UART debe crear el paquete de datos —agregando la sincronización y los bits de paridad— y enviar ese paquete por la línea TX con una sincronización precisa (de acuerdo con la velocidad de transmisión establecida). En el extremo de recepción, el UART tiene que muestrear la línea de RX a velocidades acordes con la velocidad de transmisión que se espera, seleccionar los bits de sincronización y entregar como resultado los datos.
UART interno

Los UART más avanzados pueden enviar los datos que reciben a un archivo de memoria de respaldo, llamado búfer, donde pueden permanecer hasta que el microcontrolador vaya a buscarlos. Los UART generalmente publicarán sus datos almacenados en un búfer con un sistema de “el primero que entra es el primero que sale” (First In First Out = FIFO). Los búfer pueden tener apenas unos pocos bits, o pueden ser de gran tamaño, como miles de bytes.
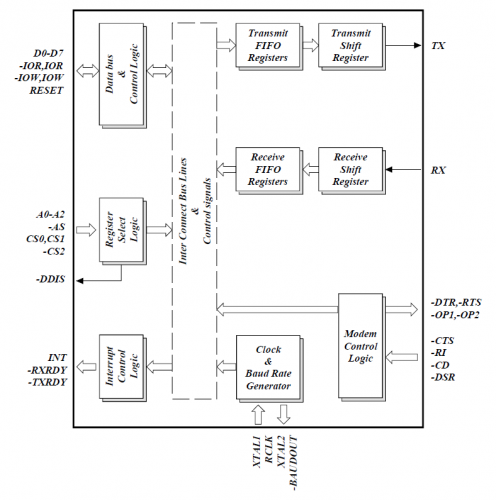
Diagrama de bloques de un UART con FIFO
UARTs de software
Si un microcontrolador no tiene un UART, o no tiene suficientes, se puede implementar la interfaz en serie en bits que son controlados directamente por el procesador. Este es el enfoque que tienen las bibliotecas de Arduino como SoftwareSerial. El uso de bits es intensivo en el procesador, y no suele ser tan preciso como un UART, pero funciona en caso de necesidad.
Errores comunes
Eso fue todo lo básico sobre la comunicación en serie. Podemos dejar señalados algunos errores comunes que un ingeniero, de cualquier nivel de experiencia, puede llegar a cometer:
RX a TX, / TX a RX
Parece bastante simple, pero es un error que algunos cometen un par de veces. Por mucho que desee que sus etiquetas coincidan, siempre asegúrese de cruzar las líneas RX y TX entre los dispositivos serie.

FTDI Basic programando un Pro Mini. Note que RX y TX están cruzados
Discrepancia en la velocidad de transmisión
Los valores de baudios son como claves en lenguajes de la comunicación en serie. Si dos dispositivos no están hablando a la misma velocidad, los datos pueden ser mal interpretados o completamente perdidos. Si todo lo que el dispositivo receptor ve en su línea de recepción está compuesta de caracteres extraños, llamados “basura” en el ambiente, verifique que coincidan las velocidades en baudios definidas en ambos extremos.
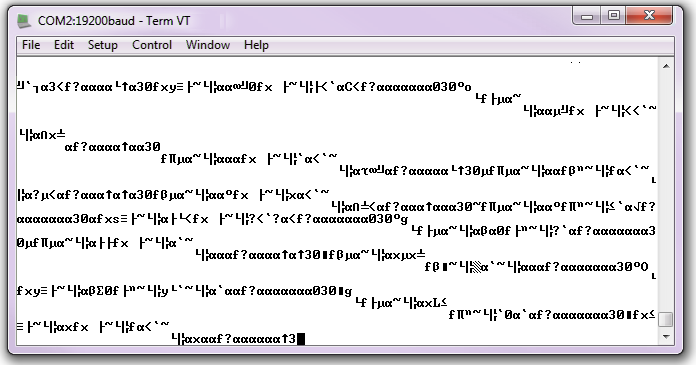
Datos transmitidos a 9600 bps, pero recibidos a 19200 bps. Desajuste de baudios = basura
Contención de transferencia en la línea
La comunicación en serie está diseñada para permitir que solo dos dispositivos se comuniquen a través de un bus en serie. Si más de un dispositivo está intentando transmitir en la misma línea serie, podría encontrarse con una contención de bus.
Por ejemplo, si está conectando un módulo GPS a su Arduino, puede conectar la línea de transmisión de ese módulo a la línea RX de Arduino. Pero ese pin Arduino RX ya está conectado al pin TX del convertidor de USB a serie (por ejemplo un chip FTDI) que se usa cada vez que se programa el Arduino, o se usa el Monitor Serie. Esto establece la situación potencial en la que tanto el módulo GPS como el chip FTDI intentan transmitir en la misma línea al mismo tiempo.
Ejemplo de contención de línea (o bus)

No es bueno que dos dispositivos intenten transmitir datos al mismo tiempo en la misma línea. En el mejor de los casos, ninguno de los dispositivos podrá enviar sus datos. En el peor de los casos, las líneas de transmisión de ambos dispositivos se volverán locas (aunque eso es raro y generalmente están protegidos contra esta situación).
Puede ser seguro conectar varios dispositivos receptores a un solo dispositivo de transmisión. Realmente no cabe dentro de las especificaciones, y probablemente esté mal visto por un ingeniero experimentado, pero funcionará. Por ejemplo, si conectamos un LCD serie a un Arduino, el método más sencillo puede ser conectar la línea RX del módulo LCD a la línea TX del Arduino. El TX de Arduino ya está conectado a la línea RX del programador USB, pero eso deja solo un dispositivo controlando la línea de transmisión.
Implementación segura pero dudosa de un transmisor y dos receptores
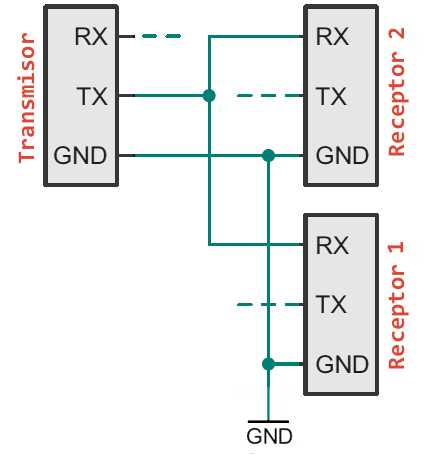
La distribución de una línea de transmisión de este tipo puede ser peligrosa desde la perspectiva del firmware, ya que no puede elegir qué dispositivo recibe cual transmisión. La pantalla LCD terminará recibiendo datos que no están destinados a ella, lo que podría ordenarle que pase a un estado desconocido.
Hay formas de implementarlo, usando un poco de hardware adicional, pero esto es tema para otro artículo.